
Japont (日本語Webフォントのダイナミックサブセット化) について
Japont (日本語Webフォントのダイナミックサブセット化) について
Japontの実装のお話です.
わかりやすく書くつもりです.
これを読んで,もっといいダイナミックサブセット化OSSを作ってくれると僕が喜びます.
日本語Webフォントの問題点
- データ量が多い
- 必要な文字だけを抽出したフォントを作っておく(静的)
- サブセッティング(サブセット化)
- 使う文字列が固定である必要がある
- 必要な文字を動的に調べ,抽出したフォントを作る(動的)
- ダイナミックサブセッティング(サブセット化)
- フォントを抽出するためのサーバとシステムが必要
- 必要な文字だけを抽出したフォントを作っておく(静的)
今回やったこと
フォントを抽出するためのシステムの開発(OSSとして公開)
おおまかな仕組み
- 必要な文字を調べる(javascript)
- 必要な文字をサーバに送信(javascript)
- 受け取った文字のコードを調べる(python, fontforge)
- 文字コードからフォントを抽出(python, fontforge)
- 生成したフォントをCSSとしてクライアントへ送信(python)
- 受け取ったCSSを反映させる(javascript)
必要な文字を調べる
サイトにある文字列は次のコードで取得できます.
var text = document.querySelector('#id').textContent;
古いブラウザでは動かないですが,これからやること自体がそういうものなので問題ありません.
取得した文字列から,重複せずに文字を抽出します.
いろいろ検討しましたが,以下の方法を使いました.
var originChars = text.split(''); var uniqueObj = {}; originChars.forEach(function(char){ uniqueObj[char] = 1; }); var uniqueChars = Object.keys(uniqueObj);
javascriptは,連想配列のキーにUnicode文字列が利用できるため,すべての文字をキーとして適当な値を代入します.
その後,連想配列のキーを配列として取得すれば完了です.
必要な文字をサーバに送信
XMLHttpRequestでPOST送信します.
受け取った文字のコードを調べる
文字コード自体の取得は簡単です.
chars = list() char_list = list(json_data['text']) for char in char_list: chars.append(ord(char))
実はこれからが問題です.
よくある例は,「日」です.
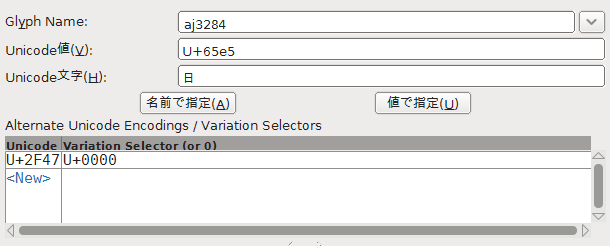
これは,IPA明朝の「日」をfontforgeで開いた画面の一部です.
下の方にあるAlternate Unicode Encodingsが参照先です.
この文字コードは,他の文字コードを参照しているので利用するには参照先も含める必要があります.
import fontforge chars = {{chars}} font = fontforge.open("{{fontpath}}") l = len(chars) for i in range(0, l): char = chars[i] try: uni = font[char].unicode #01 if uni != char: chars.append(uni) alts = font[char].altuni #02 if alts is None: continue for alt in alts: if alt[0] != char: chars.append(alt[0]) except TypeError: #03 pass
雑なコードですが,順番に説明します.
文字コードのリストすべてに対して,参照先を検索します.
#01 では,文字コードを再取得しています.
これは,参照している文字コードを選択すると,参照元の文字コードが選択されるためです.
#02 では,自身を参照している文字コードのリストを取得します.
それらに対して,自身と文字コードが違うならばリストに追加します.
#03 のエラー処理は,フォントによっては存在しない文字コードがあるためです.
存在しない文字コードを選択するとエラーが出るので,無視します.
(無視して問題ないエラーです)
文字コードからフォントを抽出
fontforgeをつかって文字を抽出します.
これについてはネットを探すとたくさん事例が出てきますので割愛.
生成したフォントをCSSとしてクライアントへ送信
フォントを配信する上で,フォントのライセンスを含めることは必須です.
フォントのライセンスとフォント自体を一緒に配信するため,両方を1つのCSSにまとめます.
CSSの先頭にコメントとしてフォントのライセンスを埋め込みます.
ここでCSSとしてフォントを埋め込むために,Data URI schemeを使います.
http://ja.wikipedia.org/wiki/Data_URI_scheme
Data URI Schemeは,base64でデータをエンコードして配信する手法です.
データ量が多少増してしまいますが,ここは目をつぶることにします.
/* {{license}} */ @font-face { font-family: '{{font_family}}'; src: url('data:application/x-font-woff;base64,{{export_base64}}') format('woff'); }
受け取ったCSSを反映させる
反映させるために,styleタグで埋め込みます.
// 大まかなコード var fontNode = document.createElement('style'); var textNode = document.createTextNode(xhr.responseText); fontNode.appendChild(textNode); document.head.appendChild(fontNode);
その他の技術
どうせモダンブラウザしか動かないと踏んだので,Custom Elementを使ってみました.
自分だけのHTMLタグを作るのは,ちょっと楽しくなってきますね.
あとがき
作ってみて動くことはわかったけれども,やっぱりサーバへの負荷がそれなりにあるよう.
Herokuだけで使えることを目標としていたけれども厳しいようです.
Dockerfileを提供する予定ではいるので,ご自身のサーバで動かしてみてください.
ちなみに,自分のサイトはConohaを使っています.